
Kombinering av språkmodeller med egne data
Av Malik Aasen
Publisert 07.07.2023
I dagens teknologilandskap hører man mye om språkmodeller, spesifikt da ChatGPT, men lite om anvendelsen av slike modeller på egne data. Sonat holdt nylig en workshop om akkurat dette, og i denne artikkelen skal vi gå gjennom oppsett av en applikasjon som tar i bruk egne data, og kommuniserer med OpenAI.
Forhåndskrav:
- Python 3.8.1+
- Valgfri container-applikasjon(Docker, podman etc)
- Kode editor
- Nettleser som lar deg inspisere elementerer
- OpenAI konto med API-nøkkel
Pakker du er nødt til å installere (les gjerne litt om de slik at du forstår begrep som blir nevnt i artikkelen):
- Langchain (https://python.langchain.com/)
- OpenAI (https://openai.com/)
- Qdrant (https://qdrant.tech/)
- Beaufitfulsoup4 (https://www.crummy.com/software/BeautifulSoup/bs4/doc/)
- Streamlit (https://streamlit.io/)
Her er link til repository: https://github.com/Sonat-Consulting/sonat-workshop-text-data/
Instruksjoner for å kjøre applikasjonen står i readme.
Språkmodeller med egne data
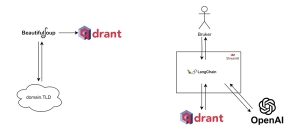
Oversikt over applikasjonen. Delt opp i datainnsamling og llm-kommunikasjon.
Scraping av nettsider med Beautiful Soup:
Applikasjonen bruker Beautiful Soup, et populært Python-bibliotek, til å scrape nettsider. Scraping er enkelt forklart bare å hente ut informasjonen som står på en nettside. For eksempel hvis du scraper hele vg.no sin forside vil du få all teksten og eventuelt bildene om du har lagt inn kode for dette.
Vi har valgt brønnøysundregistrene(brreg.no) ettersom det er enkelt å scrape. Med enkelt menes at den oppfyller kriterier som: sitemap eksisterer(Side som inneholder alle url-ene på domenet) og lik html/css struktur for alle sidene(enten i form av id eller klasse). Vi kan da hente alle sidene fra https://www.brreg.no/sitemap.xml og lagre de i f.eks en tekstfil. Vi går så inn og inspiserer et par sider for å finne fellesnevnere i sidestrukturen. I dette tilfellet befinner sideinnholdet seg i .pagecontent klassen, så vi velger den slik at vi slipper å hente inn navigasjonsmenyen og andre unyttige elementer. Det kommer fremdeles med unyttig informasjon, men for enkelhetens skyld sier vi at det er godt nok (Vi skal senere splitte opp teksten i chunks, så de irrelevante delene vil ikke produsere for mye støy).
Videre itererer vi gjennom alle sidene, og lagrer hver side som en tekstfil med følgende navnestruktur: SIDE INDEX .txt, f.eks “brreg1.txt”. Grunnen til at vi mellomlagrer sidene istedenfor å direkte laste de inn er at vi slipper å scrape på nytt igjen om vi skrur av databasen, men her står du fritt til å gjøre det som passer deg best. Noen sider vil man jo hente periodisk, og da må du implementere kode for dette.
Splitting og lagring i vektordatabase:
Etter å ha hentet dataene, deles hver nettside opp i mindre deler kalt "chunks". Hver chunk er 2000 tegn lang og overlapper med de foregående 100 tegnene. Dette gjør det mulig for modellen å fokusere på den mest relevante delen av kilden når den skal svare på spørsmål. Hver chunk blir deretter lagret som et dokument i en vektordatabase kalt Qdrant. Vektordatabser kort forklart er en database der alt lagres som vektorer, noe som er veldig gunstig ifm. likhetssøk. Her legger man også ved embedding løsningen(i dette tilfellet OpenAI sin) for å konvertere tekst til embeddings(vektorer).Tekstene blir også koblet til kildesiden, slik at vi senere kan vise til kildene når vi presenterer svarene til brukeren.
Bruk av OpenAI for spørsmål-svar-funksjonalitet:
Etter at dataen er delt og lagret i vektordatabasen, setter vi opp kommunikasjonen med OpenAI for å oppnå spørsmål-svar-funksjonalitet. Vi oppretter en klient som kobler oss til databasen, og velger hvilken modell vi ønsker å bruke. I dette tilfellet bruker vi en modell kalt gpt-3.5-turbo, fordi den gir en god balanse mellom inndatastørrelse, resultatets kvalitet og kostnaden. Vi kan også justere et parameter kjent som temperatur, som påvirker modellens kreativitet når den genererer svar.
Vi lager så en chain av oppsett som definerer logikken bak applikasjonen. En chain er en sekvensiell prosedyre som gir oss fleksibilitet til å utføre mer komplekse oppgaver enn det vi har implementert her. Det er viktig å merke seg at vi også kan forhåndsprogrammere modellen ved å gi den spesifikk informasjon på forhånd, som for eksempel struktur, språk og nøyaktighet. Denne informasjonen blir deretter en integrert del av chainen.
Når en bruker sender inn et spørsmål, går vi videre med å konvertere teksten til en embedding og deretter spør Qdrant-databasen etter de fem likeste kildene i databasen. For å sikre kvaliteten på resultatene, bruker vi en likhetsterskel (threshold) på 0,75 for å filtrere ut irrelevante kilder. Deretter sender vi både spørsmålet og de utvalgte kildene til OpenAI for å motta et svar. Når modellen er ferdig med å behandle spørsmålet, blir svaret vist til brukeren. Det er også verdt å merke seg at OpenAI API-et støtter streaming-modus, som gir en mer dynamisk chat-opplevelse, på lik linje med det vi opplever med ChatGPT.
Personvern
En viktig påminnelse er at når man bruker OpenAI så sendes spørsmålet og kildene til en amerikansk tjeneste. Derfor bør man være forsiktig med å inkludere sensitiv informasjon. Før du sender data ut, kan du muligens renske dataen for sensitiv informasjon om det lar seg gjøre. For de som ønsker mer kontroll, kan man vurdere å kjøre egne modeller, men dette kan være ressurskrevende. Man kan også vurdere Azure OpenAI dersom det tilfredsstiller dine sikkerhetskrav rundt datalagring og personvern.
Gjøre det fra scratch selv?
Om du derimot ønsker å gjøre dette på egen hånd fra scratch, så har jeg laget en generell flyt som kan være grei å følge. Du står også da fritt til valg av teknologi. Det eneste valget vi har tatt her er bruk av OpenAI sitt API.
- 1. Definer datakilden din: Dette kan være alt fra filer du har lokalt på din maskin, til scraping av en hel nettside. Om du velger en nettside kan det være gunstig å ha tilgang til en sitemap(Oversikt over alle URL-er på domenet) slik at du enkelt kan iterere gjennom disse. En sitemap kan ligge forskjellige steder, men de to stedene jeg ser de oftest er enten på domene.tld/sitemap.xml eller domene.tld/robots.txt. Det kan også være greit å sjekke om siden har en Terms of Service først, ettersom det ikke er alle nettsider som tillater fri bruk av innholdet deres.
- 2. Last det inn i en datalagringsplattform som er egnet for likhetssøk: Dette er selvfølgelig ikke et “must”, men vil gjøre jobben din enklere ettersom du uansett vil trenge dette. Vektordatabaser er ekstremt godt egnet for dette, men du har lignende in-memory løsninger som f.eks FAISS. Her bør du stykke opp kildene dine om størrelsen overskrider OpenAI sin token limit, samt konvertere dem til embeddings om ikke lagringsplatformen din har dette innebygd.
- 3. Sett opp applikasjonen din: Denne applikasjonen har to oppgaver(Tre om den skal inkludere front-end): Hente de n-likeste kildene og kommunisere med OpenAII. Dette gjøres ved at når brukeren har sendt inn spørsmålet, så hentes de n-likeste kildene ut og sendes sammen med spørsmålet til LLM-en. Her kan det være greit å tweake litt på hvor mye data man sender inn, da input og output er del av samme token limit, så om du sender veldig mye informasjon kan svaret tilbake være ganske kort.
Konklusjon
Jeg har i denne artikkelen forsøkt å demonstrere hvordan man utnytter egne tekstdata til kommunisering med en språkmodell. Vi har gått gjennom oppsett og kjøring av en applikasjon som lar deg bruke ChatGPT til å stille spørsmål relatert til egne data, tatt i bruk vektordatabase til rask querying, samt brukt BeautifulSoup til å hente informasjon fra nettsider.
Applikasjonen gir oss en enkel og effektiv måte å hente og behandle informasjon på nettet, samt generere svar på spørsmål ved hjelp av OpenAI. Den viser også hvor kraftig vektordatabaser er, og bare det kan være nyttig for mange. Ved å tilpasse koden kan man utvide funksjonaliteten og tilpasse den til spesifikke behov. Fremtiden vil sannsynligvis bringe enda mer tilgjengelige modeller for slike oppgaver, og flere leverandører og biblioteker dukker opp as we speak.
Jeg håper dere har fått nytte ut av dette, om det skulle være noen spørsmål er det bare å kontakte meg.
