En hybrid fagdag i ny drakt på Rebel!
Publisert 14.02.2022
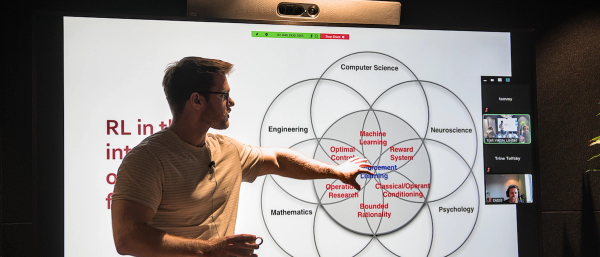
Presentasjonsteknikk
Vi er opptatt av å dele kunnskap i Sonat. Dette gir oss styrke utover egen kompetanse, og bygger forståelse mellom ulike fagdisipliner. Vi blir også oppfordret til å presentere fagkompetansen vår på en forståelig og interessant måte, slik at vi blir bedre lagspillere og brobyggere.
Det er ikke til å komme unna at det å holde presentasjoner foran et publikum ikke er alles favorittaktivitet, og forskning viser at en stor andel av oss frykter det. Så å få mer kunnskap om gode teknikker og tips for å gjøre det litt mindre skummelt å holde en presentasjon, er kjærkomment. Trine Tolfsby presenterte først teori og prinsipper for gode presentasjoner. Ønsker du å få frem budskapet ditt og bli husket, er det viktig å forstå hvordan hjernen vår tar opp informasjon og lagrer den. Vi beveget oss så utenfor komfortsonen, gjorde praktiske oppgaver og delte gode presentasjoner.

Kunstig intelligens
Kunstig intelligens har lenge vært et tema som våre konsulenter har ønsket å fordype seg i på en fagdag. Denne delen av fagdagen ble organisert av Tommy Odland og Marius Brataas, og emnet ble delt i tre sesjoner: søk, nevrale nettverk og reinforcement learning. Hver sesjon besto av en presentasjon og praktiske oppgaver.
Søk ble introdusert med utgangspunkt i elvekrysningsproblemer som praktisk eksempel. Dette er gåter der strukturen er kjent og man har et tydelig mål. Slike problemer kan løses med søk, og vi diskuterte algoritmer som DFS, BFS, A*, IDS og bidirectional search. I spill som “tre på rad”, sjakk og backgammon kan man også bruke søk, og vi presenterte søketeknikkene minimax, expectiminimax og alpha-beta pruning.
Nevrale nettverk er fleksible modeller som kan lære fra ulike typer datasett, enten det er tabeller, bilder, tekst, lyd eller annet. Etter å ha hatt en kort teoretisk gjennomgang gikk vi gjennom praktiske oppgaver i Tensorflow, som er Googles programvarebibliotek for å lage nevrale nettverk. Vi prøve oss på regresjon av tabelldata og klassifisering av bilder.
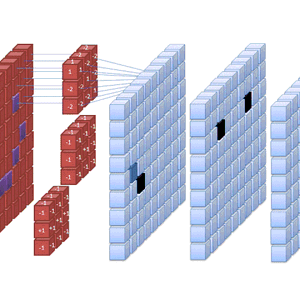

Reinforcement learning handler om å trene en agent til å utføre oppgaver i et interaktivt miljø. Agenten mottar en belønning hver gang den gjør gode valg, og lærer seg å utføre oppgaver ved å prøve og feile mange ganger. Agenten blir ikke forklart hvordan den skal utføre en oppgave, men må selv finne ut hvilke handlinger den bør ta. Vi fokuserte på Q-learning med nevrale nettverk, og løste en oppgave som går ut på å balansere en stang på en tralle i et simulert miljø (kjent som CartPole).
Vi avsluttet fagdagen med å gå helt i kjelleren, på Rebel, for en perfekt 3-retters på Disotto! Så selv om vi fikk beskjed om å ikke bli helt gestikulerende som en italiener på scenen, fikk vi i alle fall nyte italienske herligheter, både på tallerken og i glassene. Men best av alt var selskapet - det var godt å få lov til være sosial igjen!
ARRANGØRENE AV FAGDAGEN 11. FEBRUAR 2022



sdfds